For those who need a basic introduction to ontology, here is a narrower perspective oriented to data representation and sharing, which roughly covers OWL ontology semantics (initially published in 2004 as a World Wide Web Consortium specification).

As Wikipedia details, ontology is broadly a study of the nature of existence and the kinds of distinctions therein between material things or more abstract representations of things and processes. Ontology has a longstanding place in the philosophies of various cultures as recorded history reveals, but here we focus on a contemporary data science-oriented version that combines controlled vocabularies with a semantic framework, enabling both humans and computers to compare and contrast data which has been expressed in ontology terms. Specifically, computers can compare sentences expressed according to the grammar and vocabulary references that an ontology provides to see if they echo the same fact or are about the same thing(s), or are compatible or contradictory with respect to some claim.

Ontology builds on a variety of concepts, but a good place to start is with the data dictionary of computer science fame. A data dictionary is a list of terms, each accompanied by a plain language description, and possibly a data type, such as a string, number, or date. A document or database table reference to a data dictionary term (in a tagged phrase or table column label or a cell value) brings the plain language semantics of the definition and the precise syntax of the data type to bear.
Similarly, ontologists tend to call things entities, and that includes material things like a pencil, or water, as well as abstract things like an orbit around the sun. A term is a kind of entity which has a textual label, as well as a textual definition which conveys what type of thing the entity is. Importantly, an OWL ontology also has the facility to provide a globally unique identifier URI for each term, which can be set up as an ontology lookup service page that returns some or all semantic information about that term which the defining ontology (and potentially others that reference it) provides.
Each ontology term is actually a class of entity which ideally includes the characteristics (or differentiae, features, attributes, properties, qualities) it takes to recognize a given thing as a member of such a class – this is a basic ontology approach to pattern recognition. The minimal bundle of class characteristics to recognize something with are called necessary and sufficient for the categorization, and can be stated in a plain language definition. For example “An animal which has four limbs” is the definition for a quadruped class of animal. The plain language definition of a term ideally has its counterpart in an equivalence axiom – a formal logic expression consisting of entities and object properties. For example “animal and ‘has part’ exactly 4 limb” is the equivalence axiom for the quadruped class. Anything that matches this axiom will be considered a quadruped. As well there may be necessary characteristics that aren’t part of the equivalence axiom. These are basically characteristics that all members of a class will have, but they might not be used to recognize a class member by. All quadrupeds have mass for example, but that isn’t used to recognize them directly, it is more of a characteristic inherited from being a material entity.
Ontologies allow classes to be organized as subclasses of other classes, just like a taxonomic hierarchy. Any necessary or sufficient axioms associated with a parent or ancestral class are inherited by subclasses. A reasoner can even place a class (of objects) appropriately within a hierarchy of classes by looking at all the class axioms involved. Importantly, OWL ontologies offer polyhierarchy capability – a class can be expressly stated to be a child of more than one class. A “lung” is a member of several branches of the UBERON anatomy ontology, including “respiration organ”, “thoracic cavity element”, “lateral structure” and “endoderm-derived structure”; each of these contexts is important in its own right. Ideally reasoning is relied upon to categorize a class beyond its expressly stated position in a primary hierarchy. Deciding on a class’s primary hierarchy can be difficult. In the lung example one could argue that what a lung does – “respiration organ” – is more important than where it is or how it was made.
On the formal logic side, an ontology often has a set of qualitative and quantitative relations, called predicates or object properties or data properties, that can connect an entity to another entity or value (e.g. “Lasha ‘has sister’ Tula”; “Lasha ‘has age’ 7”). These form a rich set of parameters to reason or query on. Mereology, the study of parts and wholes, provides an especially important set of object properties, as does Mereotopology, which includes spatial relations that entities may be involved in. Ontology data properties often handle the work that relational database field-level data types do, but are often augmented with more semantic data structure to indicate the entity being measured, time of measurement, and units involved, for example.
Not everything in an ontology is suited to logical analysis (reasoning). One may want to adorn entities with various textual comments, synonyms, database cross references, curation status and date, etc. Such content is handled in annotation tags that can be applied to an entity. Together, object properties, data properties and annotations make up a graph data structure that can be queried using graph query languages like SPARQL.
Ontologies can be a great “lingua franca” for data sharing and harmonization provided that they do a good job of detailing data (that agencies or enterprises are interested in) regardless of the specific domain of knowledge being represented. In other words, the more that a given set of ontologies can appear as a single language (grammar and basic vocabulary pattern) that data implementers and analysts can apply as they represent or navigate through various domains of knowledge, the less learning load and expense occurs, and the more likely data meets FAIR data standards.
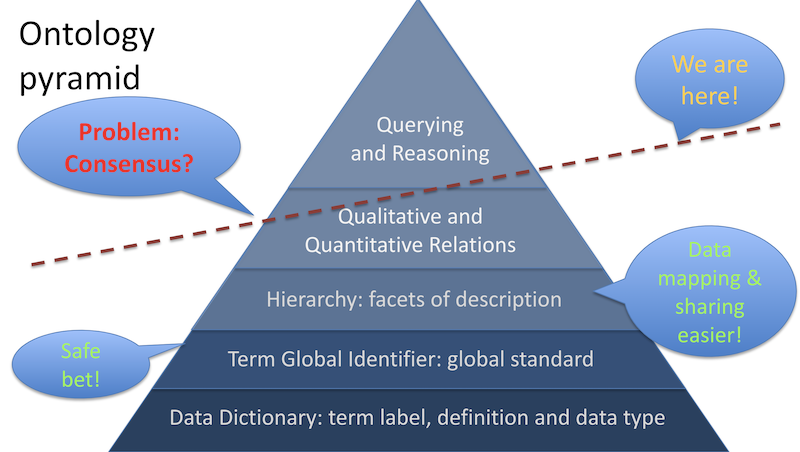
As the diagram above conveys, at the top of the ontology pyramid we are promised a landscape of federated data sets which can be queried and reasoned over using a language common to them all. In reality semantic web technology has not yet arrived fully at that station. There are various ontology communities with somewhat different upper level paradigms about how the world should be represented, or which have dispensed with upper level generalities and just offer up their own more domain-specific relations that become parts of a representation and querying landscape one must master to access related data. A pragmatic approach in the face of disjoint ontologies is to map semantically equivalent or similar concepts and then generate harmonized dataset views which can be queried. That is hopefully a temporary step on the longer route to a harmonized and simplified ontology scene.
One note, a union of one or more ontologies doesn’t preclude containing different senses of a term catering to different user groups if each sense can be distinguished by a unique term identifier, and backed up by a textual definition that explains the different semantics or context of use. Whether computers fully comprehend the different usages depends on the axioms attached to each term variation, but the fact that they have unique identifiers allows databases to register the different uses. It also helps to reflect the speech community variant usage of a term in its label, either by noting the language variant of a label (e.g. british or american usage), or via synonymy annotations.
Secondly, the motivation for creating different ontologies about a domain of interest sometimes lies in the perception that one community of user doesn’t need the detail and complexity that another user community needs. This speaks to a need for more work and education on how to develop modelling that uses the same language (general entities and relationships) but can simultaneously provide different levels of descriptive granularity pitched at the needs of each community.

Ontologies are in the digital age what dictionaries were in the age of print. Depending on its ambitions, the curation of an ontology may resemble the great dictionary work of the past, and so it is worth pointing out that this is a highly collaborative and time intensive process. James Murray, initial editor of the Oxford English Dictionary (OED) over 140 years ago, optimistically predicted the OED would take five years, but in the end, even with the help of his children, the general public, and a prisoner with scholarly time on his hands, it took over 35 years to finish the first edition.
With FoodOn we have a growing group of curators and a head start consisting of the many hierarchic terms provided as an initial seed by LanguaL, so we remain as optimistic as James was!